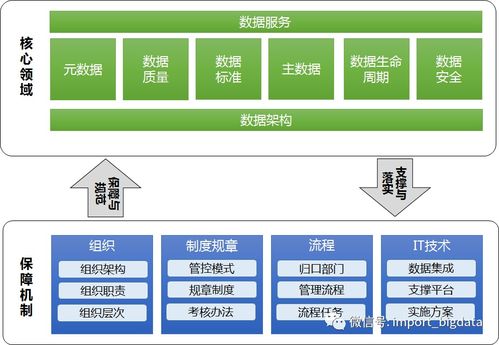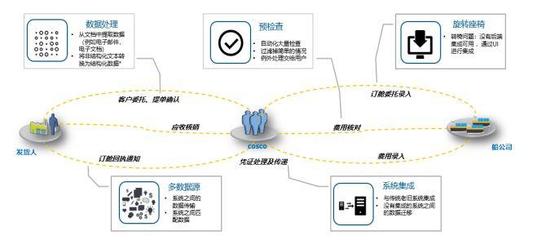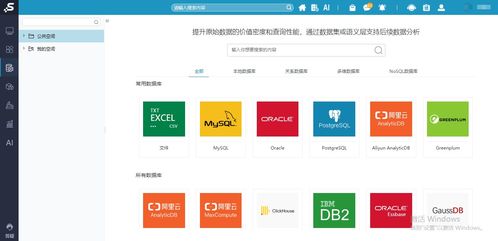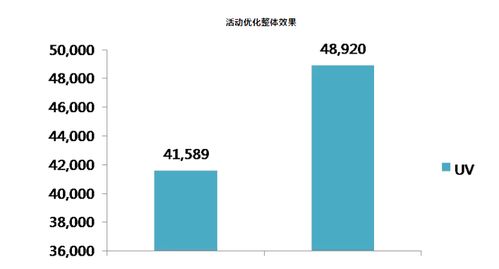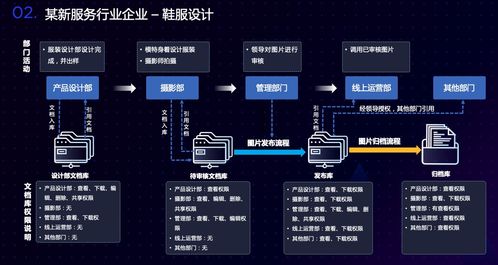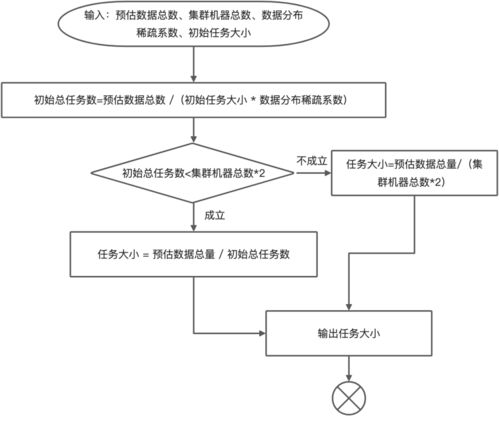
在当今大数据时代,亿级数据的聚合处理已成为许多企业和组织的核心需求。传统的数据处理方法在面对海量数据时往往效率低下,甚至无法完成任务。因此,开发一种高效、可扩展的亿级聚合数据处理方法至关重要。
数据分片是处理亿级聚合数据的基础。通过将数据划分为多个较小的片段,可以并行处理这些片段,显著提高处理速度。例如,可以使用哈希分片或范围分片策略,将数据均匀分布到多个计算节点上。这种方法不仅减少了单个节点的负载,还充分利用了分布式系统的计算能力。
采用分布式计算框架是实现高效聚合的关键。Apache Spark、Flink等现代计算框架提供了强大的聚合功能,支持内存计算和容错机制。以Spark为例,其RDD(弹性分布式数据集)和DataFrame API可以轻松实现分组、求和、计数等聚合操作,并通过优化执行计划提升性能。对于亿级数据,Spark的分布式聚合能够将任务分解为多个阶段,并在集群中并行执行,大大缩短处理时间。
数据预处理和索引优化也是不可忽视的环节。在聚合之前,对数据进行清洗、去重和压缩,可以减少不必要的计算开销。同时,为常用聚合字段建立索引,如使用布隆过滤器或B树索引,可以加速数据查找和聚合过程。例如,在时间序列数据聚合中,按时间戳建立索引可以快速定位特定时间范围的数据,提升聚合效率。
资源管理和监控是确保系统稳定运行的重要保障。通过动态资源分配和负载均衡,系统可以根据数据量和计算需求自动调整资源使用。监控工具如Prometheus或Grafana可以帮助实时跟踪聚合任务的进度和性能指标,及时发现并解决瓶颈问题。
通过数据分片、分布式计算框架、数据预处理与索引优化以及资源管理监控,我们可以构建一种高效处理亿级聚合数据的方法。这种方法不仅提升了数据处理速度,还保证了系统的可扩展性和稳定性,适用于电商、金融、物联网等多个领域的大数据应用场景。